Wstęp
Kluczowym w procesie pisania programów w Javie jest zrozumienie pojęć stojących za takimi hasłami jak kompilacja, interpretowanie kodu, czy Just-In-Time compiler (JIT) albo Wirtualna Maszyna Javy(JVM). Dlaczego to ważne? No np. dlatego, że rzadko kiedy piszemy w Javie nie używając absolutnie żadnych frameworków. Nie chcę tutaj rozpętywać żadnej wojny i mówić co o tym myślę, bo chociaż osobiście nie jestem fanem Springa, SpringBoota, czy innych pochodnych frameworków, to jednak bądźmy szczerzy… Jeżeli mamy mało czasu, a potrzebny jest prosty restowy crudzik do opierdzielenia, to niech pierwszy rzuci kamieniem ten kto nie sięgnie po SpringBoota i nie napisze tego kodu w xmlu zaciągając odpowiednie zależności… No więc te frameworki potrafią modyfikować kod bajtowy na podstawie własnych instrukcji umieszczonych w samym frameworku. Właśnie dzięki temu użycie jednej magicznej adnotacji potrafi wygenerować cały zestaw klas, które w innym przypadku musielibyśmy sami napisać. Dzisiaj na tapet weźmiemy kod bajtowy oraz maszynowy. Dlatego warto zapamiętać, że:
Rezultatem kompilowania kodu w Javie jest kod bajtowy (byte code).
Rezultatem interpretowania kodu bajtowego jest kod maszynowy (machine code).
Najprościej te różnice wyjaśnić na podstawie poniższego diagramu:
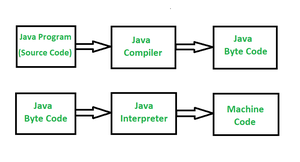
źródło: https://www.geeksforgeeks.org/difference-between-byte-code-and-machine-code/
Warto również tutaj podkreślić, że samo używanie kodu bajtowego wynika z podejścia twórców języka do tworzenia aplikacji w Javie w taki sposób, żeby były wieloplatformowe. Kod bajtowy jest językiem uniwersalnym. Weźmy np. język C++, gdzie tego typu podejście nie jest stosowane. Tam proces kompilacji sprowadza się do:
Program w C++ — [Kompilacja] —> Kod Maszynowy
Byte Code
Kod bajtowy (intermediate-level code) [*.class] to niezależny od platformy zestaw instrukcji wygenerowanych w procesie kompilacji z kodu źródłowego [np. *.java] języków jvmowych, czyli niekoniecznie musi być to Java, dla Wirtualnej Maszyny Java. To zestaw makro instrukcji w formacie hexadecymalnym, które nie będą w bezpośredni sposób zrozumiałe dla CPU. Klientem końcowym dla kodu bajtowego musi być JVM.
Machine Code
Kod maszynowy (low-level code) to zestaw instrukcji w formacie binarnym procesowanych przez CPU (nie JVM) zależny od platformy.
Co dalej?
Jeżeli ciekawi Was bardziej jak wygląda zawartość pliku .class (wynik kompilacji) to odsyłam do świetnego materiału przygotowanego przez Tobiasza:
Linki:
- https://www.geeksforgeeks.org/difference-between-byte-code-and-machine-code/
- Specyfikacja JVM
- https://ichi.pro/pl/wprowadzenie-do-kodu-bajtowego-java-ktorego-nie-znasz-37818474908344
Can you tell us more about this? I’d love to find out some additional information.